pyxu.abc#
pyxu.abc.arithmetic#
- class Rule[source]#
Bases:
objectGeneral arithmetic rule.
This class defines default arithmetic rules applicable unless re-defined by sub-classes.
- class ScaleRule(op, cst)[source]#
Bases:
RuleArithmetic rules for element-wise scaling: \(B(x) = \alpha A(x)\).
Special Cases:
\alpha = 0 => NullOp/NullFunc \alpha = 1 => self
Else:
|--------------------------|-------------|--------------------------------------------------------------------| | Property | Preserved? | Arithmetic Update Rule(s) | |--------------------------|-------------|--------------------------------------------------------------------| | CAN_EVAL | yes | op_new.apply(arr) = op_old.apply(arr) * \alpha | | | | op_new.lipschitz = op_old.lipschitz * abs(\alpha) | |--------------------------|-------------|--------------------------------------------------------------------| | FUNCTIONAL | yes | | |--------------------------|-------------|--------------------------------------------------------------------| | PROXIMABLE | \alpha > 0 | op_new.prox(arr, tau) = op_old.prox(arr, tau * \alpha) | |--------------------------|-------------|--------------------------------------------------------------------| | DIFFERENTIABLE | yes | op_new.jacobian(arr) = op_old.jacobian(arr) * \alpha | | | | op_new.diff_lipschitz = op_old.diff_lipschitz * abs(\alpha) | |--------------------------|-------------|--------------------------------------------------------------------| | DIFFERENTIABLE_FUNCTION | yes | op_new.grad(arr) = op_old.grad(arr) * \alpha | |--------------------------|-------------|--------------------------------------------------------------------| | QUADRATIC | \alpha > 0 | Q, c, t = op_old._quad_spec() | | | | op_new._quad_spec() = (\alpha * Q, \alpha * c, \alpha * t) | |--------------------------|-------------|--------------------------------------------------------------------| | LINEAR | yes | op_new.adjoint(arr) = op_old.adjoint(arr) * \alpha | | | | op_new.asarray() = op_old.asarray() * \alpha | | | | op_new.svdvals() = op_old.svdvals() * abs(\alpha) | | | | op_new.pinv(x, damp) = op_old.pinv(x, damp / (\alpha**2)) / \alpha | | | | op_new.gram() = op_old.gram() * (\alpha**2) | | | | op_new.cogram() = op_old.cogram() * (\alpha**2) | |--------------------------|-------------|--------------------------------------------------------------------| | LINEAR_SQUARE | yes | op_new.trace() = op_old.trace() * \alpha | |--------------------------|-------------|--------------------------------------------------------------------| | LINEAR_NORMAL | yes | | |--------------------------|-------------|--------------------------------------------------------------------| | LINEAR_UNITARY | \alpha = -1 | | |--------------------------|-------------|--------------------------------------------------------------------| | LINEAR_SELF_ADJOINT | yes | | |--------------------------|-------------|--------------------------------------------------------------------| | LINEAR_POSITIVE_DEFINITE | \alpha > 0 | | |--------------------------|-------------|--------------------------------------------------------------------| | LINEAR_IDEMPOTENT | no | | |--------------------------|-------------|--------------------------------------------------------------------|
- class ArgScaleRule(op, cst)[source]#
Bases:
RuleArithmetic rules for element-wise parameter scaling: \(B(x) = A(\alpha x)\).
Special Cases:
\alpha = 0 => ConstantValued (w/ potential vector-valued output) \alpha = 1 => self
Else:
|--------------------------|-------------|-----------------------------------------------------------------------------| | Property | Preserved? | Arithmetic Update Rule(s) | |--------------------------|-------------|-----------------------------------------------------------------------------| | CAN_EVAL | yes | op_new.apply(arr) = op_old.apply(arr * \alpha) | | | | op_new.lipschitz = op_old.lipschitz * abs(\alpha) | |--------------------------|-------------|-----------------------------------------------------------------------------| | FUNCTIONAL | yes | | |--------------------------|-------------|-----------------------------------------------------------------------------| | PROXIMABLE | yes | op_new.prox(arr, tau) = op_old.prox(\alpha * arr, \alpha**2 * tau) / \alpha | |--------------------------|-------------|-----------------------------------------------------------------------------| | DIFFERENTIABLE | yes | op_new.diff_lipschitz = op_old.diff_lipschitz * (\alpha**2) | | | | op_new.jacobian(arr) = op_old.jacobian(arr * \alpha) * \alpha | |--------------------------|-------------|-----------------------------------------------------------------------------| | DIFFERENTIABLE_FUNCTION | yes | op_new.grad(arr) = op_old.grad(\alpha * arr) * \alpha | |--------------------------|-------------|-----------------------------------------------------------------------------| | QUADRATIC | yes | Q, c, t = op_old._quad_spec() | | | | op_new._quad_spec() = (\alpha**2 * Q, \alpha * c, t) | |--------------------------|-------------|-----------------------------------------------------------------------------| | LINEAR | yes | op_new.adjoint(arr) = op_old.adjoint(arr) * \alpha | | | | op_new.asarray() = op_old.asarray() * \alpha | | | | op_new.svdvals() = op_old.svdvals() * abs(\alpha) | | | | op_new.pinv(x, damp) = op_old.pinv(x, damp / (\alpha**2)) / \alpha | | | | op_new.gram() = op_old.gram() * (\alpha**2) | | | | op_new.cogram() = op_old.cogram() * (\alpha**2) | |--------------------------|-------------|-----------------------------------------------------------------------------| | LINEAR_SQUARE | yes | op_new.trace() = op_old.trace() * \alpha | |--------------------------|-------------|-----------------------------------------------------------------------------| | LINEAR_NORMAL | yes | | |--------------------------|-------------|-----------------------------------------------------------------------------| | LINEAR_UNITARY | \alpha = -1 | | |--------------------------|-------------|-----------------------------------------------------------------------------| | LINEAR_SELF_ADJOINT | yes | | |--------------------------|-------------|-----------------------------------------------------------------------------| | LINEAR_POSITIVE_DEFINITE | \alpha > 0 | | |--------------------------|-------------|-----------------------------------------------------------------------------| | LINEAR_IDEMPOTENT | no | | |--------------------------|-------------|-----------------------------------------------------------------------------|
- class ArgShiftRule(op, cst)[source]#
Bases:
RuleArithmetic rules for parameter shifting: \(B(x) = A(x + c)\).
Special Cases:
[NUMPY,CUPY] \shift = 0 => self [DASK] \shift = 0 => rules below apply ... ... because we don't force evaluation of \shift for performance reasons.
Else:
|--------------------------|------------|-----------------------------------------------------------------| | Property | Preserved? | Arithmetic Update Rule(s) | |--------------------------|------------|-----------------------------------------------------------------| | CAN_EVAL | yes | op_new.apply(arr) = op_old.apply(arr + \shift) | | | | op_new.lipschitz = op_old.lipschitz | |--------------------------|------------|-----------------------------------------------------------------| | FUNCTIONAL | yes | | |--------------------------|------------|-----------------------------------------------------------------| | PROXIMABLE | yes | op_new.prox(arr, tau) = op_old.prox(arr + \shift, tau) - \shift | |--------------------------|------------|-----------------------------------------------------------------| | DIFFERENTIABLE | yes | op_new.diff_lipschitz = op_old.diff_lipschitz | | | | op_new.jacobian(arr) = op_old.jacobian(arr + \shift) | |--------------------------|------------|-----------------------------------------------------------------| | DIFFERENTIABLE_FUNCTION | yes | op_new.grad(arr) = op_old.grad(arr + \shift) | |--------------------------|------------|-----------------------------------------------------------------| | QUADRATIC | yes | Q, c, t = op_old._quad_spec() | | | | op_new._quad_spec() = (Q, c + Q @ \shift, op_old.apply(\shift)) | |--------------------------|------------|-----------------------------------------------------------------| | LINEAR | no | | |--------------------------|------------|-----------------------------------------------------------------| | LINEAR_SQUARE | no | | |--------------------------|------------|-----------------------------------------------------------------| | LINEAR_NORMAL | no | | |--------------------------|------------|-----------------------------------------------------------------| | LINEAR_UNITARY | no | | |--------------------------|------------|-----------------------------------------------------------------| | LINEAR_SELF_ADJOINT | no | | |--------------------------|------------|-----------------------------------------------------------------| | LINEAR_POSITIVE_DEFINITE | no | | |--------------------------|------------|-----------------------------------------------------------------| | LINEAR_IDEMPOTENT | no | | |--------------------------|------------|-----------------------------------------------------------------|
- class AddRule(lhs, rhs)[source]#
Bases:
RuleArithmetic rules for operator addition: \(C(x) = A(x) + B(x)\).
The output type of
AddRule(A, B)is summarized in the table below (LHS/RHS commute):|---------------|-----|------|---------|----------|----------|--------------|-----------|---------|--------------|------------|------------|------------|---------------|---------------|------------|---------------| | LHS / RHS | Map | Func | DiffMap | DiffFunc | ProxFunc | ProxDiffFunc | Quadratic | LinOp | LinFunc | SquareOp | NormalOp | UnitOp | SelfAdjointOp | PosDefOp | ProjOp | OrthProjOp | |---------------|-----|------|---------|----------|----------|--------------|-----------|---------|--------------|------------|------------|------------|---------------|---------------|------------|---------------| | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | | Func | | Func | Map | Func | Func | Func | Func | Map | Func | Map | Map | Map | Map | Map | Map | Map | | DiffMap | | | DiffMap | DiffMap | Map | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | | DiffFunc | | | | DiffFunc | Func | DiffFunc | DiffFunc | DiffMap | DiffFunc | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | | ProxFunc | | | | | Func | Func | Func | Map | ProxFunc | Map | Map | Map | Map | Map | Map | Map | | ProxDiffFunc | | | | | | DiffFunc | DiffFunc | DiffMap | ProxDiffFunc | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | | Quadratic | | | | | | | Quadratic | DiffMap | Quadratic | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | | LinOp | | | | | | | | LinOp | LinOp | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | | LinFunc | | | | | | | | | LinFunc | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | SquareOp | | | | | | | | | | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | NormalOp | | | | | | | | | | | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | UnitOp | | | | | | | | | | | | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | SelfAdjointOp | | | | | | | | | | | | | SelfAdjointOp | SelfAdjointOp | SquareOp | SelfAdjointOp | | PosDefOp | | | | | | | | | | | | | | PosDefOp | SquareOp | PosDefOp | | ProjOp | | | | | | | | | | | | | | | SquareOp | SquareOp | | OrthProjOp | | | | | | | | | | | | | | | | SelfAdjointOp | |---------------|-----|------|---------|----------|----------|--------------|-----------|---------|--------------|------------|------------|------------|---------------|---------------|------------|---------------|
Arithmetic Update Rule(s):
* CAN_EVAL op.apply(arr) = _lhs.apply(arr) + _rhs.apply(arr) op.lipschitz = _lhs.lipschitz + _rhs.lipschitz IMPORTANT: if range-broadcasting takes place (ex: LHS(1,) + RHS(M,)), then the broadcasted operand's Lipschitz constant must be magnified by \sqrt{M}. * PROXIMABLE op.prox(arr, tau) = _lhs.prox(arr - tau * _rhs.grad(arr), tau) OR = _rhs.prox(arr - tau * _lhs.grad(arr), tau) IMPORTANT: the one calling .grad() should be either (lhs, rhs) which has LINEAR property * DIFFERENTIABLE op.jacobian(arr) = _lhs.jacobian(arr) + _rhs.jacobian(arr) op.diff_lipschitz = _lhs.diff_lipschitz + _rhs.diff_lipschitz IMPORTANT: if range-broadcasting takes place (ex: LHS(1,) + RHS(M,)), then the broadcasted operand's diff-Lipschitz constant must be magnified by \sqrt{M}. * DIFFERENTIABLE_FUNCTION op.grad(arr) = _lhs.grad(arr) + _rhs.grad(arr) * LINEAR op.adjoint(arr) = _lhs.adjoint(arr) + _rhs.adjoint(arr) IMPORTANT: if range-broadcasting takes place (ex: LHS(1,) + RHS(M,)), then the broadcasted operand's adjoint-input must be averaged. op.asarray() = _lhs.asarray() + _rhs.asarray() op.gram() = _lhs.gram() + _rhs.gram() + (_lhs.T * _rhs) + (_rhs.T * _lhs) op.cogram() = _lhs.cogram() + _rhs.cogram() + (_lhs * _rhs.T) + (_rhs * _lhs.T) * LINEAR_SQUARE op.trace() = _lhs.trace() + _rhs.trace() * QUADRATIC lhs = rhs = quadratic Q_l, c_l, t_l = lhs._quad_spec() Q_r, c_r, t_r = rhs._quad_spec() op._quad_spec() = (Q_l + Q_r, c_l + c_r, t_l + t_r) lhs, rhs = quadratic, linear Q, c, t = lhs._quad_spec() op._quad_spec() = (Q, c + rhs, t)
- class ChainRule(lhs, rhs)[source]#
Bases:
RuleArithmetic rules for operator composition: \(C(x) = (A \circ B)(x)\).
The output type of
ChainRule(A, B)is summarized in the table below:|---------------|------|------------|----------|------------|------------|----------------|----------------------|------------------|------------|-----------|-----------|--------------|---------------|-----------|-----------|------------| | LHS / RHS | Map | Func | DiffMap | DiffFunc | ProxFunc | ProxDiffFunc | Quadratic | LinOp | LinFunc | SquareOp | NormalOp | UnitOp | SelfAdjointOp | PosDefOp | ProjOp | OrthProjOp | |---------------|------|------------|----------|------------|------------|----------------|----------------------|------------------|------------|-----------|-----------|--------------|---------------|-----------|-----------|------------| | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | Map | | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | | DiffMap | Map | Map | DiffMap | DiffMap | Map | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | DiffMap | | DiffFunc | Func | Func | DiffFunc | DiffFunc | Func | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | | ProxFunc | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | Func | ProxFunc | Func | Func | Func | Func | | ProxDiffFunc | Func | Func | DiffFunc | DiffFunc | Func | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | ProxDiffFunc | DiffFunc | DiffFunc | DiffFunc | DiffFunc | | Quadratic | Func | Func | DiffFunc | DiffFunc | Func | DiffFunc | DiffFunc | Quadratic | Quadratic | Quadratic | Quadratic | Quadratic | Quadratic | Quadratic | Quadratic | Quadratic | | LinOp | Map | Func | DiffMap | DiffMap | Map | DiffMap | DiffMap | LinOp / SquareOp | LinOp | LinOp | LinOp | LinOp | LinOp | LinOp | LinOp | LinOp | | LinFunc | Func | Func | DiffFunc | DiffFunc | [Prox]Func | [Prox]DiffFunc | DiffFunc / Quadratic | LinFunc | LinFunc | LinFunc | LinFunc | LinFunc | LinFunc | LinFunc | LinFunc | LinFunc | | SquareOp | Map | IMPOSSIBLE | DiffMap | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | LinOp | IMPOSSIBLE | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | NormalOp | Map | IMPOSSIBLE | DiffMap | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | LinOp | IMPOSSIBLE | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | UnitOp | Map | IMPOSSIBLE | DiffMap | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | LinOp | IMPOSSIBLE | SquareOp | SquareOp | UnitOp | SquareOp | SquareOp | SquareOp | SquareOp | | SelfAdjointOp | Map | IMPOSSIBLE | DiffMap | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | LinOp | IMPOSSIBLE | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | PosDefOp | Map | IMPOSSIBLE | DiffMap | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | LinOp | IMPOSSIBLE | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | ProjOp | Map | IMPOSSIBLE | DiffMap | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | LinOp | IMPOSSIBLE | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | | OrthProjOp | Map | IMPOSSIBLE | DiffMap | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | IMPOSSIBLE | LinOp | IMPOSSIBLE | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | SquareOp | |---------------|------|------------|----------|------------|------------|----------------|----------------------|------------------|------------|-----------|-----------|--------------|---------------|-----------|-----------|------------|
Arithmetic Update Rule(s):
* CAN_EVAL op.apply(arr) = _lhs.apply(_rhs.apply(arr)) op.lipschitz = _lhs.lipschitz * _rhs.lipschitz * PROXIMABLE (RHS Unitary only) op.prox(arr, tau) = _rhs.adjoint(_lhs.prox(_rhs.apply(arr), tau)) * DIFFERENTIABLE op.jacobian(arr) = _lhs.jacobian(_rhs.apply(arr)) * _rhs.jacobian(arr) op.diff_lipschitz = quadratic => _quad_spec().Q.lipschitz linear \comp linear => 0 linear \comp diff => _lhs.lipschitz * _rhs.diff_lipschitz diff \comp linear => _lhs.diff_lipschitz * (_rhs.lipschitz ** 2) diff \comp diff => \infty * DIFFERENTIABLE_FUNCTION (1D input) op.grad(arr) = _lhs.grad(_rhs.apply(arr)) @ _rhs.jacobian(arr).asarray() * LINEAR op.adjoint(arr) = _rhs.adjoint(_lhs.adjoint(arr)) op.asarray() = _lhs.asarray() @ _rhs.asarray() op.gram() = _rhs.T @ _lhs.gram() @ _rhs op.cogram() = _lhs @ _rhs.cogram() @ _lhs.T * QUADRATIC Q, c, t = _lhs._quad_spec() op._quad_spec() = (_rhs.T * Q * _rhs, _rhs.T * c, t)
- class TransposeRule(op)[source]#
Bases:
RuleArithmetic rules for
LinOptransposition: \(B(x) = A^{T}(x)\).Arithmetic Update Rule(s):
* CAN_EVAL opT.apply(arr) = op.adjoint(arr) opT.lipschitz = op.lipschitz * PROXIMABLE opT.prox(arr, tau) = LinFunc.prox(arr, tau) * DIFFERENTIABLE opT.jacobian(arr) = opT opT.diff_lipschitz = 0 * DIFFERENTIABLE_FUNCTION opT.grad(arr) = LinFunc.grad(arr) * LINEAR opT.adjoint(arr) = op.apply(arr) opT.asarray() = op.asarray().T [block-reorder dim/codim] opT.gram() = op.cogram() opT.cogram() = op.gram() opT.svdvals() = op.svdvals() * LINEAR_SQUARE opT.trace() = op.trace()
- Parameters:
op (OpT)
pyxu.abc.operator#
- class Property(value, names=<not given>, *values, module=None, qualname=None, type=None, start=1, boundary=None)[source]#
Bases:
EnumMathematical property.
See also
- CAN_EVAL = 1#
- FUNCTIONAL = 2#
- PROXIMABLE = 3#
- DIFFERENTIABLE = 4#
- DIFFERENTIABLE_FUNCTION = 5#
- LINEAR = 6#
- LINEAR_SQUARE = 7#
- LINEAR_NORMAL = 8#
- LINEAR_IDEMPOTENT = 9#
- LINEAR_SELF_ADJOINT = 10#
- LINEAR_POSITIVE_DEFINITE = 11#
- LINEAR_UNITARY = 12#
- QUADRATIC = 13#
- class Operator(dim_shape, codim_shape)[source]#
Bases:
objectAbstract Base Class for Pyxu operators.
Goals:
enable operator arithmetic.
cast operators to specialized forms.
attach
Propertytags encoding certain mathematical properties. Each core sub-class must have a unique set of properties to be distinguishable from its peers.
- Parameters:
- __init__(dim_shape, codim_shape)[source]#
- Parameters:
dim_shape (
NDArrayShape) – (M1,…,MD) operator input shape.codim_shape (
NDArrayShape) – (N1,…,NK) operator output shape.
- property codim_shape: Integral | tuple[Integral, ...]#
Return shape of operator’s co-domain. (N1,…,NK)
- classmethod has(prop)[source]#
Verify if operator possesses supplied properties.
- Parameters:
prop (Property | Collection[Property])
- Return type:
- asop(cast_to)[source]#
Recast an
Operator(or subclass thereof) to anotherOperator.Users may call this method if the arithmetic API yields sub-optimal return types.
This method is a no-op if
cast_tois a parent class ofself.- Parameters:
cast_to (
OpC) – Target type for the recast.- Returns:
op – Operator with the new interface.
Fails when cast is forbidden. (Ex:
Map->Funcif codim.size > 1)- Return type:
Notes
The interface of
cast_tois provided via encapsulation + forwarding.If
selfdoes not implement all methods fromcast_to, then unimplemented methods will raiseNotImplementedErrorwhen called.
- __add__(other)[source]#
Add two operators.
- Parameters:
- Returns:
op – Composite operator
self + other- Return type:
Notes
Operand shapes must be consistent, i.e.:
have
same dimensions, andhave
compatible co-dimensions(after broadcasting).
See also
- __mul__(other)[source]#
Compose two operators, or scale an operator by a constant.
- Parameters:
- Returns:
op – Scaled operator or composed operator
self * other.- Return type:
Notes
If called with two operators, their shapes must be
consistent, i.e.self.dim_shape == other.codim_shape.
- argshift(shift)[source]#
Shift operator’s domain.
- Parameters:
shift (
NDArray) –Shift value \(c \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\).
shiftmust be broadcastable with operator’s dimension.- Returns:
op – Domain-shifted operator \(g(x) = f(x + c)\).
- Return type:
See also
- expr(level=0, strip=True)[source]#
Pretty-Print the expression representation of the operator.
Useful for debugging arithmetic-induced expressions.
Example
import numpy as np import pyxu.abc as pxa kwargs = dict(dim_shape=5, codim_shape=5) op1 = pxa.LinOp(**kwargs) op2 = pxa.DiffMap(**kwargs) op = ((2 * op1) + (op1 * op2)).argshift(np.r_[1]) print(op.expr()) # [argshift, ==> DiffMap(dim=(5,), codim=(5,)) # .[add, ==> DiffMap(dim=(5,), codim=(5,)) # ..[scale, ==> LinOp(dim=(5,), codim=(5,)) # ...LinOp(dim=(5,), codim=(5,)), # ...2.0], # ..[compose, ==> DiffMap(dim=(5,), codim=(5,)) # ...LinOp(dim=(5,), codim=(5,)), # ...DiffMap(dim=(5,), codim=(5,))]], # .(1,)]
- class Map(dim_shape, codim_shape)[source]#
Bases:
OperatorBase class for real-valued maps \(\mathbf{f}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\).
Instances of this class must implement
apply().If \(\mathbf{f}\) is Lipschitz-continuous with known Lipschitz constant \(L\), the latter should be stored in the
lipschitzproperty.- Parameters:
- property lipschitz: Real#
Return the last computed Lipschitz constant of \(\mathbf{f}\).
Notes
If a Lipschitz constant is known apriori, it can be stored in the instance as follows:
class TestOp(Map): def __init__(self, dim_shape, codim_shape): super().__init__(dim_shape, codim_shape) self.lipschitz = 2 op = TestOp(2, 3) op.lipschitz # => 2
Alternatively the Lipschitz constant can be set manually after initialization:
class TestOp(Map): def __init__(self, dim_shape, codim_shape): super().__init__(dim_shape, codim_shape) op = TestOp(2, 3) op.lipschitz # => inf, since unknown apriori op.lipschitz = 2 # post-init specification op.lipschitz # => 2
lipschitz()never computes anything: callestimate_lipschitz()manually to compute a new Lipschitz estimate:op.lipschitz = op.estimate_lipschitz()
- estimate_lipschitz(**kwargs)[source]#
Compute a Lipschitz constant of the operator.
- Parameters:
kwargs (
Mapping) – Class-specific kwargs to configure Lipschitz estimation.- Return type:
Notes
This method should always be callable without specifying any kwargs.
A constant \(L_{\mathbf{f}} > 0\) is said to be a Lipschitz constant for a map \(\mathbf{f}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\) if:
\[\|\mathbf{f}(\mathbf{x}) - \mathbf{f}(\mathbf{y})\|_{\mathbb{R}^{N_{1} \times\cdots\times N_{K}}} \leq L_{\mathbf{f}} \|\mathbf{x} - \mathbf{y}\|_{\mathbb{R}^{M_{1} \times\cdots\times M_{D}}}, \qquad \forall \mathbf{x}, \mathbf{y}\in \mathbb{R}^{M_{1} \times\cdots\times M_{D}},\]where \(\|\cdot\|_{\mathbb{R}^{M_{1} \times\cdots\times M_{D}}}\) and \(\|\cdot\|_{\mathbb{R}^{N_{1} \times\cdots\times N_{K}}}\) are the canonical norms on their respective spaces.
The smallest Lipschitz constant of a map is called the optimal Lipschitz constant.
- class Func(dim_shape, codim_shape)[source]#
Bases:
MapBase class for real-valued functionals \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}\cup\{+\infty\}\).
Instances of this class must implement
apply().If \(f\) is Lipschitz-continuous with known Lipschitz constant \(L\), the latter should be stored in the
lipschitzproperty.
- class DiffMap(dim_shape, codim_shape)[source]#
Bases:
MapBase class for real-valued differentiable maps \(\mathbf{f}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\).
Instances of this class must implement
apply()andjacobian().If \(\mathbf{f}\) is Lipschitz-continuous with known Lipschitz constant \(L\), the latter should be stored in the
lipschitzproperty.If \(\mathbf{J}_{\mathbf{f}}\) is Lipschitz-continuous with known Lipschitz constant \(\partial L\), the latter should be stored in the
diff_lipschitzproperty.- Parameters:
- jacobian(arr)[source]#
Evaluate the Jacobian of \(\mathbf{f}\) at the specified point.
- Parameters:
arr (
NDArray) – (M1,…,MD) evaluation point.- Returns:
op – Jacobian operator at point
arr.- Return type:
Notes
Let \(\mathbf{f}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\) be a differentiable multi-dimensional map. The Jacobian (or differential) of \(\mathbf{f}\) at \(\mathbf{z} \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\) is defined as the best linear approximator of \(\mathbf{f}\) near \(\mathbf{z}\), in the following sense:
\[\mathbf{f}(\mathbf{x}) - \mathbf{f}(\mathbf{z}) = \mathbf{J}_{\mathbf{f}}(\mathbf{z}) (\mathbf{x} - \mathbf{z}) + o(\| \mathbf{x} - \mathbf{z} \|) \quad \text{as} \quad \mathbf{x} \to \mathbf{z}.\]The Jacobian admits the following matrix representation:
\[[\mathbf{J}_{\mathbf{f}}(\mathbf{x})]_{ij} := \frac{\partial f_{i}}{\partial x_{j}}(\mathbf{x}), \qquad \forall (i,j) \in \{1,\ldots,N_{1}\cdots N_{K}\} \times \{1,\ldots,M_{1}\cdots M_{D}\}.\]
- property diff_lipschitz: Real#
Return the last computed Lipschitz constant of \(\mathbf{J}_{\mathbf{f}}\).
Notes
If a diff-Lipschitz constant is known apriori, it can be stored in the instance as follows:
class TestOp(DiffMap): def __init__(self, dim_shape, codim_shape): super().__init__(dim_shape, codim_shape) self.diff_lipschitz = 2 op = TestOp(2, 3) op.diff_lipschitz # => 2
Alternatively the diff-Lipschitz constant can be set manually after initialization:
class TestOp(DiffMap): def __init__(self, dim_shape, codim_shape): super().__init__(dim_shape, codim_shape) op = TestOp(2, 3) op.diff_lipschitz # => inf, since unknown apriori op.diff_lipschitz = 2 # post-init specification op.diff_lipschitz # => 2
diff_lipschitz()never computes anything: callestimate_diff_lipschitz()manually to compute a new diff-Lipschitz estimate:op.diff_lipschitz = op.estimate_diff_lipschitz()
- estimate_diff_lipschitz(**kwargs)[source]#
Compute a Lipschitz constant of
jacobian().- Parameters:
kwargs (
Mapping) – Class-specific kwargs to configure diff-Lipschitz estimation.- Return type:
Notes
This method should always be callable without specifying any kwargs.
A Lipschitz constant \(L_{\mathbf{J}_{\mathbf{f}}} > 0\) of the Jacobian map \(\mathbf{J}_{\mathbf{f}}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{(N_{1} \times\cdots\times N_{K}) \times (M_{1} \times\cdots\times M_{D})}\) is such that:
\[\|\mathbf{J}_{\mathbf{f}}(\mathbf{x}) - \mathbf{J}_{\mathbf{f}}(\mathbf{y})\|_{\mathbb{R}^{(N_{1} \times\cdots\times N_{K}) \times (M_{1} \times\cdots\times M_{D})}} \leq L_{\mathbf{J}_{\mathbf{f}}} \|\mathbf{x} - \mathbf{y}\|_{\mathbb{R}^{M_{1} \times\cdots\times M_{D}}}, \qquad \forall \mathbf{x}, \mathbf{y} \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}},\]where \(\|\cdot\|_{\mathbb{R}^{(N_{1} \times\cdots\times N_{K}) \times (M_{1} \times\cdots\times M_{D})}}\) and \(\|\cdot\|_{\mathbb{R}^{M_{1} \times\cdots\times M_{D}}}\) are the canonical norms on their respective spaces.
The smallest Lipschitz constant of the Jacobian is called the optimal diff-Lipschitz constant.
- class DiffFunc(dim_shape, codim_shape)[source]#
-
Base class for real-valued differentiable functionals \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}\).
Instances of this class must implement
apply()andgrad().If \(f\) and/or its derivative \(f'\) are Lipschitz-continuous with known Lipschitz constants \(L\) and \(\partial L\), the latter should be stored in the
lipschitzanddiff_lipschitzproperties.- Parameters:
- grad(arr)[source]#
Evaluate operator gradient at specified point(s).
- Parameters:
arr (
NDArray) – (…, M1,…,MD) input points.- Returns:
out – (…, M1,…,MD) gradients.
- Return type:
Notes
The gradient of a functional \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}\) is given, for every \(\mathbf{x} \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\), by
\[\begin{split}\nabla f(\mathbf{x}) := \left[\begin{array}{c} \frac{\partial f}{\partial x_{1}}(\mathbf{x}) \\ \vdots \\ \frac{\partial f}{\partial x_{M}}(\mathbf{x}) \end{array}\right].\end{split}\]
- class ProxFunc(dim_shape, codim_shape)[source]#
Bases:
FuncBase class for real-valued proximable functionals \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R} \cup \{+\infty\}\).
A functional \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R} \cup \{+\infty\}\) is said proximable if its proximity operator (see
prox()for a definition) admits a simple closed-form expression or can be evaluated efficiently and with high accuracy.Instances of this class must implement
apply()andprox().If \(f\) is Lipschitz-continuous with known Lipschitz constant \(L\), the latter should be stored in the
lipschitzproperty.- Parameters:
- prox(arr, tau)[source]#
Evaluate proximity operator of \(\tau f\) at specified point(s).
- Parameters:
- Returns:
out – (…, M1,…,MD) proximal evaluations.
- Return type:
Notes
For \(\tau >0\), the proximity operator of a scaled functional \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}\) is defined as:
\[\mathbf{\text{prox}}_{\tau f}(\mathbf{z}) := \arg\min_{\mathbf{x}\in\mathbb{R}^{M_{1} \times\cdots\times M_{D}}} f(x)+\frac{1}{2\tau} \|\mathbf{x}-\mathbf{z}\|_{2}^{2}, \quad \forall \mathbf{z} \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}}.\]
- fenchel_prox(arr, sigma)[source]#
Evaluate proximity operator of \(\sigma f^{\ast}\), the scaled Fenchel conjugate of \(f\), at specified point(s).
- Parameters:
- Returns:
out – (…, M1,…,MD) proximal evaluations.
- Return type:
Notes
For \(\sigma > 0\), the Fenchel conjugate is defined as:
\[f^{\ast}(\mathbf{z}) := \max_{\mathbf{x}\in\mathbb{R}^{M_{1} \times\cdots\times M_{D}}} \langle \mathbf{x},\mathbf{z} \rangle - f(\mathbf{x}).\]From Moreau’s identity, its proximal operator is given by:
\[\mathbf{\text{prox}}_{\sigma f^{\ast}}(\mathbf{z}) = \mathbf{z} - \sigma \mathbf{\text{prox}}_{f/\sigma}(\mathbf{z}/\sigma).\]
- moreau_envelope(mu)[source]#
Approximate proximable functional \(f\) by its Moreau envelope \(f^{\mu}\).
- Parameters:
mu (
Real) – Positive regularization parameter.- Returns:
op – Differential Moreau envelope.
- Return type:
Notes
Consider a convex non-smooth proximable functional \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R} \cup \{+\infty\}\) and a regularization parameter \(\mu > 0\). The \(\mu\)-Moreau envelope (or Moreau-Yoshida envelope) of \(f\) is given by
\[f^{\mu}(\mathbf{x}) = \min_{\mathbf{z} \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}}} f(\mathbf{z}) \quad + \quad \frac{1}{2\mu} \|\mathbf{x} - \mathbf{z}\|^{2}.\]The parameter \(\mu\) controls the trade-off between the regularity properties of \(f^{\mu}\) and the approximation error incurred by the Moreau-Yoshida regularization.
The Moreau envelope inherits the convexity of \(f\) and is gradient-Lipschitz (with Lipschitz constant \(\mu^{-1}\)), even if \(f\) is non-smooth. Its gradient is moreover given by:
\[\nabla f^{\mu}(\mathbf{x}) = \mu^{-1} \left(\mathbf{x} - \text{prox}_{\mu f}(\mathbf{x})\right).\]In addition, \(f^{\mu}\) envelopes \(f\) from below: \(f^{\mu}(\mathbf{x}) \leq f(\mathbf{x})\). This envelope becomes tighter as \(\mu \to 0\):
\[\lim_{\mu \to 0} f^{\mu}(\mathbf{x}) = f(\mathbf{x}).\]Finally, it can be shown that the minimizers of \(f\) and \(f^{\mu}\) coincide, and that the Fenchel conjugate of \(f^{\mu}\) is strongly-convex.
Example
Construct and plot the Moreau envelope of the \(\ell_{1}\)-norm:
import numpy as np import matplotlib.pyplot as plt from pyxu.abc import ProxFunc class L1Norm(ProxFunc): def __init__(self, dim: int): super().__init__(dim_shape=dim, codim_shape=1) def apply(self, arr): return np.linalg.norm(arr, axis=-1, keepdims=True, ord=1) def prox(self, arr, tau): return np.clip(np.abs(arr)-tau, a_min=0, a_max=None) * np.sign(arr) mu = [0.1, 0.5, 1] f = [L1Norm(dim=1).moreau_envelope(_mu) for _mu in mu] x = np.linspace(-1, 1, 512).reshape(-1, 1) # evaluation points fig, ax = plt.subplots(ncols=2) for _mu, _f in zip(mu, f): ax[0].plot(x, _f(x), label=f"mu={_mu}") ax[1].plot(x, _f.grad(x), label=f"mu={_mu}") ax[0].set_title('Moreau Envelope') ax[1].set_title("Derivative of Moreau Envelope") for _ax in ax: _ax.legend() _ax.set_aspect("equal") fig.tight_layout()
(
Source code,png,hires.png,pdf)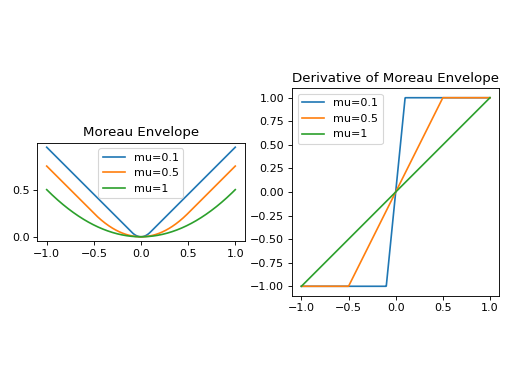
{kind=link}
{kind=link}
- class ProxDiffFunc(dim_shape, codim_shape)[source]#
-
Base class for real-valued differentiable and proximable functionals \(f:\mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}\).
Instances of this class must implement
apply(),grad(), andprox().If \(f\) and/or its derivative \(f'\) are Lipschitz-continuous with known Lipschitz constants \(L\) and \(\partial L\), the latter should be stored in the
lipschitzanddiff_lipschitzproperties.
- class QuadraticFunc(dim_shape, codim_shape, Q=None, c=None, t=0)[source]#
Bases:
ProxDiffFuncBase class for quadratic functionals \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R} \cup \{+\infty\}\).
The quadratic functional is defined as:
\[f(\mathbf{x}) = \frac{1}{2} \langle\mathbf{x}, \mathbf{Q}\mathbf{x}\rangle + \langle\mathbf{c},\mathbf{x}\rangle + t, \qquad \forall \mathbf{x} \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}},\]where \(Q\) is a positive-definite operator \(\mathbf{Q}:\mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\), \(\mathbf{c} \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\), and \(t > 0\).
Its gradient is given by:
\[\nabla f(\mathbf{x}) = \mathbf{Q}\mathbf{x} + \mathbf{c}.\]Its proximity operator by:
\[\text{prox}_{\tau f}(x) = \left( \mathbf{Q} + \tau^{-1} \mathbf{Id} \right)^{-1} \left( \tau^{-1}\mathbf{x} - \mathbf{c} \right).\]In practice the proximity operator is evaluated via
CG.The Lipschitz constant \(L\) of a quadratic on an unbounded domain is unbounded. The Lipschitz constant \(\partial L\) of \(\nabla f\) is given by the spectral norm of \(\mathbf{Q}\).
- Parameters:
- class LinOp(dim_shape, codim_shape)[source]#
Bases:
DiffMapBase class for real-valued linear operators \(\mathbf{A}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\).
Instances of this class must implement
apply()andadjoint().If known, the Lipschitz constant \(L\) should be stored in the
lipschitzproperty.The Jacobian of a linear map \(\mathbf{A}\) is constant.
- Parameters:
- adjoint(arr)[source]#
Evaluate operator adjoint at specified point(s).
- Parameters:
arr (
NDArray) – (…, N1,…,NK) input points.- Returns:
out – (…, M1,…,MD) adjoint evaluations.
- Return type:
Notes
The adjoint \(\mathbf{A}^{\ast}: \mathbb{R}^{N_{1} \times\cdots\times N_{K}} \to \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\) of \(\mathbf{A}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\) is defined as:
\[\langle \mathbf{x}, \mathbf{A}^{\ast}\mathbf{y}\rangle_{\mathbb{R}^{M_{1} \times\cdots\times M_{D}}} := \langle \mathbf{A}\mathbf{x}, \mathbf{y}\rangle_{\mathbb{R}^{N_{1} \times\cdots\times N_{K}}}, \qquad \forall (\mathbf{x},\mathbf{y})\in \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \times \mathbb{R}^{N_{1} \times\cdots\times N_{K}}.\]
- estimate_lipschitz(**kwargs)[source]#
Compute a Lipschitz constant of the operator.
- Parameters:
- Return type:
Notes
The tightest Lipschitz constant is given by the spectral norm of the operator \(\mathbf{A}\): \(\|\mathbf{A}\|_{2}\). It can be computed via the SVD, which is compute-intensive task for large operators. In this setting, it may be advantageous to overestimate the Lipschitz constant with the Frobenius norm of \(\mathbf{A}\) since \(\|\mathbf{A}\|_{F} \geq \|\mathbf{A}\|_{2}\).
\(\|\mathbf{A}\|_{F}\) can be efficiently approximated by computing the trace of \(\mathbf{A}^{\ast} \mathbf{A}\) (or \(\mathbf{A}\mathbf{A}^{\ast}\)) via the Hutch++ stochastic algorithm.
\(\|\mathbf{A}\|_{F}\) is upper-bounded by \(\|\mathbf{A}\|_{F} \leq \sqrt{n} \|\mathbf{A}\|_{2}\), where the equality is reached (worst-case scenario) when the eigenspectrum of the linear operator is flat.
- svdvals(k, gpu=False, dtype=None, **kwargs)[source]#
Compute leading singular values of the linear operator.
- Parameters:
- Returns:
D – (k,) singular values in ascending order.
- Return type:
- asarray(xp=None, dtype=None)[source]#
Matrix representation of the linear operator.
- Parameters:
xp (
ArrayModule) – Which array module to use to represent the output. (Default: NumPy.)dtype (
DType) – Precision of the array. (Default: current runtime precision.)
- Returns:
A – (*codim_shape, *dim_shape) array-representation of the operator.
- Return type:
Note
This generic implementation assumes the operator is backend-agnostic. Thus, when defining a new backend-specific operator,
asarray()may need to be overriden.
- gram()[source]#
Gram operator \(\mathbf{A}^{\ast} \mathbf{A}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\).
- Returns:
op – Gram operator.
- Return type:
Note
By default the Gram is computed by the composition
self.T * self. This may not be the fastest way to compute the Gram operator. If the Gram can be computed more efficiently (e.g. with a convolution), the user should re-define this method.
- cogram()[source]#
Co-Gram operator \(\mathbf{A}\mathbf{A}^{\ast}:\mathbb{R}^{N_{1} \times\cdots\times N_{K}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\).
- Returns:
op – Co-Gram operator.
- Return type:
Note
By default the co-Gram is computed by the composition
self * self.T. This may not be the fastest way to compute the co-Gram operator. If the co-Gram can be computed more efficiently (e.g. with a convolution), the user should re-define this method.
- pinv(arr, damp, kwargs_init=None, kwargs_fit=None)[source]#
Evaluate the Moore-Penrose pseudo-inverse \(\mathbf{A}^{\dagger}\) at specified point(s).
- Parameters:
- Returns:
out – (…, M1,…,MD) pseudo-inverse(s).
- Return type:
Notes
The Moore-Penrose pseudo-inverse of an operator \(\mathbf{A}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\) is defined as the operator \(\mathbf{A}^{\dagger}: \mathbb{R}^{N_{1} \times\cdots\times N_{K}} \to \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\) verifying the Moore-Penrose conditions:
\(\mathbf{A} \mathbf{A}^{\dagger} \mathbf{A} = \mathbf{A}\),
\(\mathbf{A}^{\dagger} \mathbf{A} \mathbf{A}^{\dagger} = \mathbf{A}^{\dagger}\),
\((\mathbf{A}^{\dagger} \mathbf{A})^{\ast} = \mathbf{A}^{\dagger} \mathbf{A}\),
\((\mathbf{A} \mathbf{A}^{\dagger})^{\ast} = \mathbf{A} \mathbf{A}^{\dagger}\).
This operator exists and is unique for any finite-dimensional linear operator. The action of the pseudo-inverse \(\mathbf{A}^{\dagger} \mathbf{y}\) for every \(\mathbf{y} \in \mathbb{R}^{N_{1} \times\cdots\times N_{K}}\) can be computed in matrix-free fashion by solving the normal equations:
\[\mathbf{A}^{\ast} \mathbf{A} \mathbf{x} = \mathbf{A}^{\ast} \mathbf{y} \quad\Leftrightarrow\quad \mathbf{x} = \mathbf{A}^{\dagger} \mathbf{y}, \quad \forall (\mathbf{x}, \mathbf{y}) \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \times \mathbb{R}^{N_{1} \times\cdots\times N_{K}}.\]In the case of severe ill-conditioning, it is possible to consider the dampened normal equations for a numerically-stabler approximation of \(\mathbf{A}^{\dagger} \mathbf{y}\):
\[(\mathbf{A}^{\ast} \mathbf{A} + \tau I) \mathbf{x} = \mathbf{A}^{\ast} \mathbf{y},\]where \(\tau > 0\) corresponds to the
dampparameter.
- dagger(damp, kwargs_init=None, kwargs_fit=None)[source]#
Return the Moore-Penrose pseudo-inverse operator \(\mathbf{A}^\dagger\).
- Parameters:
- Returns:
op – Moore-Penrose pseudo-inverse operator.
- Return type:
- class SquareOp(dim_shape, codim_shape)[source]#
Bases:
LinOpBase class for square linear operators, i.e. \(\mathbf{A}: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}^{M_{1} \times\cdots\times M_{D}}\) (endomorphsisms).
- Parameters:
- class NormalOp(dim_shape, codim_shape)[source]#
Bases:
SquareOpBase class for normal operators.
Normal operators satisfy the relation \(\mathbf{A} \mathbf{A}^{\ast} = \mathbf{A}^{\ast} \mathbf{A}\). It can be shown that an operator is normal iff it is unitarily diagonalizable, i.e. \(\mathbf{A} = \mathbf{U} \mathbf{D} \mathbf{U}^{\ast}\).
- class SelfAdjointOp(dim_shape, codim_shape)[source]#
Bases:
NormalOpBase class for self-adjoint operators.
Self-adjoint operators satisfy the relation \(\mathbf{A}^{\ast} = \mathbf{A}\).
- class UnitOp(dim_shape, codim_shape)[source]#
Bases:
NormalOpBase class for unitary operators.
Unitary operators satisfy the relation \(\mathbf{A} \mathbf{A}^{\ast} = \mathbf{A}^{\ast} \mathbf{A} = I\).
- class ProjOp(dim_shape, codim_shape)[source]#
Bases:
SquareOpBase class for projection operators.
Projection operators are idempotent, i.e. \(\mathbf{A}^{2} = \mathbf{A}\).
- class OrthProjOp(dim_shape, codim_shape)[source]#
Bases:
ProjOp,SelfAdjointOpBase class for orthogonal projection operators.
Orthogonal projection operators are idempotent and self-adjoint, i.e. \(\mathbf{A}^{2} = \mathbf{A}\) and \(\mathbf{A}^{\ast} = \mathbf{A}\).
- class PosDefOp(dim_shape, codim_shape)[source]#
Bases:
SelfAdjointOpBase class for positive-definite operators.
- class LinFunc(dim_shape, codim_shape)[source]#
Bases:
ProxDiffFunc,LinOpBase class for real-valued linear functionals \(f: \mathbb{R}^{M_{1} \times\cdots\times M_{D}} \to \mathbb{R}\).
Instances of this class must implement
apply(), andadjoint().If known, the Lipschitz constant \(L\) should be stored in the
lipschitzproperty.
pyxu.abc.solver#
- class Solver(*, folder=None, exist_ok=False, stop_rate=1, writeback_rate=None, verbosity=None, show_progress=True, log_var=frozenset({}))[source]#
Bases:
objectIterative solver for minimization problems of the form \(\hat{x} = \arg\min_{x \in \mathbb{R}^{M_{1} \times\cdots\times M_{D}}} \mathcal{F}(x)\), where the form of \(\mathcal{F}\) is solver-dependent.
Solver provides a versatile API for solving optimisation problems, with the following features:
manual/automatic/background execution of solver iterations via parameters provided to
fit(). (See below.)automatic checkpointing of solver progress, providing a safe restore point in case of faulty numerical code. Each solver instance backs its state and final output to a folder on disk for post-analysis. In particular
fit()should never crash: detailed exception information will always be available in a logfile for post-analysis.arbitrary specification of complex stopping criteria via the
StoppingCriterionclass.solve for multiple initial points in parallel. (Not always supported by all solvers.)
To implement a new iterative solver, users need to sub-class
Solverand overwrite the methods below:m_init()[i.e. math-init()]m_step()[i.e. math-step()]default_stop_crit()[optional; see method definition for details]objective_func()[optional; see method definition for details]
Advanced functionalities of
Solverare automatically inherited by sub-classes.Examples
Here are examples on how to solve minimization problems with this class:
slvr = Solver() ### 1. Blocking mode: .fit() does not return until solver has stopped. >>> slvr.fit(mode=SolverMode.BLOCK, ...) >>> data, hist = slvr.stats() # final output of solver. ### 2. Async mode: solver iterations run in the background. >>> slvr.fit(mode=SolverMode.ASYNC, ...) >>> print('test') # you can do something in between. >>> slvr.busy() # or check whether the solver already stopped. >>> slvr.stop() # and preemptively force it to stop. >>> data, hist = slvr.stats() # then query the result after a (potential) force-stop. ### 3. Manual mode: fine-grain control of solver data per iteration. >>> slvr.fit(mode=SolverMode.MANUAL, ...) >>> for data in slvr.steps(): ... # Do something with the logged variables after each iteration. ... pass # solver has stopped after the loop. >>> data, hist = slvr.stats() # final output of solver.
- Parameters:
- __init__(*, folder=None, exist_ok=False, stop_rate=1, writeback_rate=None, verbosity=None, show_progress=True, log_var=frozenset({}))[source]#
- Parameters:
folder (
Path) – Directory on disk where instance data should be stored. A location will be automatically chosen if unspecified. (Default: OS-dependent tempdir.)exist_ok (
bool) – Iffolderis specified andexist_okis false (default),FileExistsErroris raised if the target directory already exists.stop_rate (
Integer) – Rate at which solver evaluates stopping criteria.writeback_rate (
Integer) –Rate at which solver checkpoints are written to disk:
If
None(default), all checkpoints are disabled: the final solver output is only stored in memory.If
0, intermediate checkpoints are disabled: only the final solver output will be written to disk.Any other integer: checkpoint to disk at provided interval. Must be a multiple of
stop_rate.
verbosity (
Integer) – Rate at which stopping criteria statistics are logged. Must be a multiple ofstop_rate. Defaults tostop_rateif unspecified.show_progress (
bool) – If True (default) andfit()is run with mode=BLOCK, then statistics are also logged to stdout.log_var (
VarName) – Variables from the solver’s math-state (_mstate) to be logged per iteration. These are the variables made available when callingstats().
Notes
Partial device<>CPU synchronization takes place when stopping-criteria are evaluated. Increasing
stop_rateis advised to reduce the effect of such transfers when applicable.Full device<>CPU synchronization takes place at checkpoint-time. Increasing
writeback_rateis advised to reduce the effect of such transfers when applicable.
- fit(**kwargs)[source]#
Solve minimization problem(s) defined in
__init__(), with the provided run-specifc parameters.- Parameters:
kwargs – See class-level docstring for class-specific keyword parameters.
stop_crit (
StoppingCriterion) – Stopping criterion to end solver iterations. If unspecified, defaults todefault_stop_crit().mode (
SolverMode) –Execution mode. See
Solverfor usage examples.Useful method pairs depending on the execution mode:
track_objective (
bool) – Auto-compute objective function every time stopping criterion is evaluated.
- m_init(**kwargs)[source]#
Set solver’s initial mathematical state based on kwargs provided to
fit().This method must only manipulate
_mstate.After calling this method, the solver must be able to complete its 1st iteration via a call to
m_step().
- steps(n=None)[source]#
Generator of logged variables after each iteration.
The i-th call to
next()on this object returns the logged variables after the i-th solver iteration.This method is only usable after calling
fit()with mode=MANUAL. SeeSolverfor usage examples.There is no guarantee that a checkpoint on disk exists when the generator is exhausted. (Reason: potential exceptions raised during solver’s progress.) Users should invoke
writeback()afterwards if needed.
- stats()[source]#
Query solver state.
- Returns:
data (
Mapping) – Value(s) oflog_var(s) after last iteration.history (
numpy.ndarray,None) – (N_iter,) records of stopping-criteria values sampled everystop_rateiteration.
- Return type:
Notes
If any of the
log_var(s) and/orhistoryare not (yet) known at query time,Noneis returned.
- property workdir: str | Path#
- Returns:
wd – Absolute path to the directory on disk where instance data is stored.
- Return type:
- property logfile: str | Path#
- Returns:
lf – Absolute path to the log file on disk where stopping criteria statistics are logged.
- Return type:
- property datafile: str | Path#
- Returns:
df – Absolute path to the file on disk where
log_var(s) are stored during checkpointing or after solver has stopped.- Return type:
- busy()[source]#
Test if an async-running solver has stopped.
This method is only usable after calling
fit()with mode=ASYNC. SeeSolverfor usage examples.- Returns:
b – True if solver has stopped, False otherwise.
- Return type:
- solution()[source]#
Output the “solution” of the optimization problem.
This is a helper method intended for novice users. The return type is sub-class dependent, so don’t write an API using this: use
stats()instead.
- stop()[source]#
Stop an async-running solver.
This method is only usable after calling
fit()with mode=ASYNC. SeeSolverfor usage examples.This method will block until the solver has stopped.
There is no guarantee that a checkpoint on disk exists once halted. (Reason: potential exceptions raised during solver’s progress.) Users should invoke
writeback()afterwards if needed.Users must call this method to terminate an async-solver, even if
busy()is False.
- default_stop_crit()[source]#
Default stopping criterion for solver if unspecified in
fit()calls.Sub-classes are expected to overwrite this method. If not overridden, then omitting the
stop_critparameter infit()is forbidden.- Return type:
- objective_func()[source]#
Evaluate objective function given current math state.
The output array must have shape:
(1,) if evaluated at 1 point,
(N, 1) if evaluated at N different points.
Sub-classes are expected to overwrite this method. If not overridden, then enabling
track_objectiveinfit()is forbidden.- Return type:
- class SolverMode(value, names=<not given>, *values, module=None, qualname=None, type=None, start=1, boundary=None)[source]#
Bases:
EnumSolver execution mode.
- BLOCK = 1#
- MANUAL = 2#
- ASYNC = 3#
- class StoppingCriterion[source]#
Bases:
objectState machines (SM) which decide when to stop iterative solvers by examining their mathematical state.
SM decisions are always accompanied by at least one numerical statistic. These stats may be queried by solvers via
info()to provide diagnostic information to users.Composite stopping criteria can be implemented via the overloaded (and[
&], or[|]) operators.- clear()[source]#
Clear SM state (if any).
This method is useful when a
StoppingCriterioninstance must be reused in another call tofit().